
Event Sourcing in .NET Core – part 1: a gentle introduction
Event sourcing, aka “the great myth”. I’ve been thinking about writing a series of articles about this for a while, and now it’s time to put my hands back on the keyboard.
I thought that with all this bull$@#it pandemic at least I could have had more time to write on this blog but it turns out the reality has been slightly different so far.
Anyways let’s get back in track! Event sourcing. It’s probably one of the hardest things to code, immediately after two other things.
Everything that happens around us is an event of some sort. The cake is ready in the oven. The bus has arrived at the stop. Your cellphone’s battery runs out. And for every event, there might be zero or more actors reacting to it. Cause and effect, we could say.
So how does it translate for us? Event sourcing, at its heart, basically means storing all the events occurring on our system in a timely-ordered fashion. All of our write operations are basically appending to a log-like persistence storage and that’s it. Events can only be appended. Not updated or deleted.
Then what? How do we query our data? Here we get the reaction part.
Event sourcing has a very important pre-requisite: CQRS. All the read operations have to be performed on a different datastore, which is in turn populated by the appropriate event handlers.
I know it might sound a bit complex (and actually it is), so let’s try with an example.
Imagine you’re writing the software for a bank. The system can:
- create customers
- create accounts for the customers
- withdraw money from an account
- deposit money on an account
Armed with these infos, we can start modeling our commands:
- create a customer
- create an account for a customer
- withdraw money from an account
- deposit money on an account
We’ll keep it simple and won’t be dwelling much into domain-specific details like currency conversion and the like. Although DDD is another aspect that is essential to our success (and we discussed it already).
Let’s see our queries now:
- archive of customers, each with the number of open accounts
- customer details with the list of accounts, each with its balance
- list of transactions on an account
At 10,000ft. the system looks more or less like this:
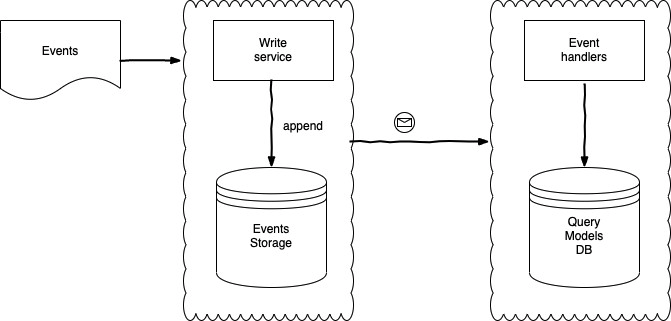
Events get pushed into the Write side which does basically two things:
- appends them to a storage system
- pushes integration events to a queue
Eventually, the integration events will be captured and consumed by the relative handlers on the Query side, materializing all the Query Models our system needs.
Now, why in the world one would even think about implementing a system like this? Well, there are quite a few good reasons.
Keeping track of what happens in an append-only storage allows replaying the events and rebuild the state of our domain models at any time. In case something bad occurs, we have an almost immediate way to understand what went wrong and possibly how to fix the issue.
Performance and scalability. The Query Models can be built with whatever technology fits the needs. Data can be persisted in a relational db, in a NoSQL one or just plain HTML. Whatever is faster and more suited for the job. Basically, if the business needs change we can quickly adapt and generate completely new forms of the models.
Moreover, the Query DBs can be wiped out and repopulated from scratch by simply replaying all the events. This gives the possibility to avoid potentially problematic things like migrations or even backups since all you have to do is just run the events again and you get the models back.
So where’s the catch? Well, the drawbacks are a few as well. We’ll talk about them in another post of this series. Next time instead we’ll take a look at a possible implementation of our bank example and we’ll start talking about how to get events into the system.
If you’re working on Azure, don’t miss my other Articles!
Did you like this post? Then




