
Event Sourcing on Azure – part 1: architecture plan
Hi All! With this post, we’ll start a new Series about Event Sourcing on Azure. We’re going to talk a bit about the pattern, general architecture, and the individual building blocks. Then in the next posts, we’ll dig more and see each one in detail.
If you’re a regular reader of this blog, you might know that I wrote already about Event Sourcing in the past. It’s a complex pattern, probably one of the most complex to get right. I enjoy the challenges it gives and how it causes a whole plethora of other patterns to be evaluated in conjunction (CQRS anyone?).
And like any other pattern, there are no silver bullets. Architecture and implementation will change based on the Domain needs.
But we can “quickly” lay out the general idea, and then diverge from it based on our necessities (or should I say the business necessities).
So let’s start with the architecture!
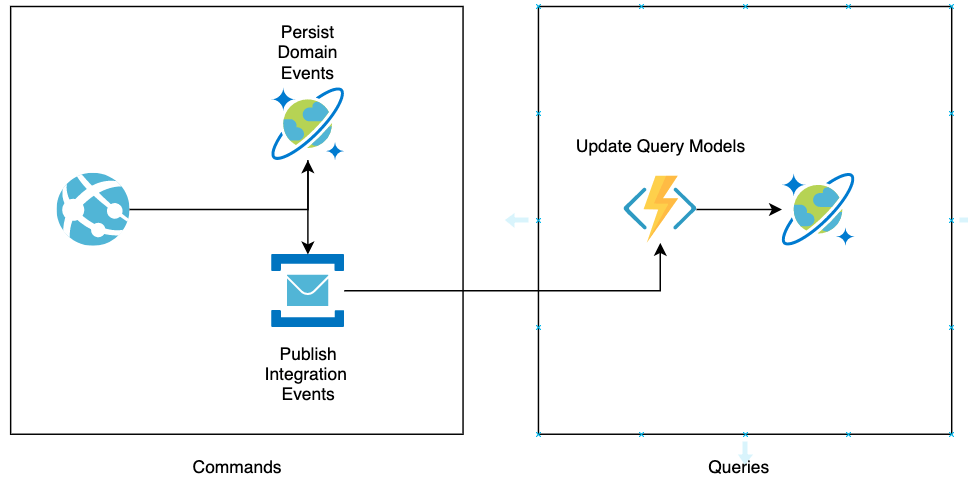
On the left we have the Commands (or Write Side), let’s begin with that. The Commands our system exposes will be accessed via REST endpoints through a Web API. We could use Azure Functions with an HTTP trigger as well, but we’ll talk more about this in another post of the Series.
Whatever way we pick to communicate with the outer world, the commands will first go through a validation phase against the business rules. This usually happens by re-hydrating the Aggregate Root from past events and performing a set of operations on it.
Then, if everything is fine, the commands be translated into Domain Events and persisted in our Event Store. We will be using CosmosDB for this.
Then we have to publish Integration Events to inform other parts of the system that “something” happened. This will be handled by Azure Service Bus Topics. We’ll use Topics instead of simple Queues because we might have different consumer types interested in a particular event type. And of course, we want to deploy, operate, and scale those consumers independently.
One of these consumers will be an Azure Functions App with a very important role: materializing our Query Models. When querying data, we can’t, of course, rehydrate the Aggregates each time. Yes, we would get consistent data each time, but it would be overkill, even if we were using snapshots.
So we subscribe to the Topics and each time we receive an event, we refresh a query-specific version of the data and we store it in another storage. We will still be using CosmosDB in our example.
Materialized views have the great benefit of being exactly what our calling application needs, including all the possible aggregated data. Moreover, in case our requirements change, we can always add new views or update the existing ones. As long as we have the original events stream, we can flush all the views and rebuild them from scratch with little cost.
That’s all for today. Next time we’ll see how we can handle events persistence. Ciao!
Did you like this post? Then




